Documentation Index
Fetch the complete documentation index at: https://docs.morphllm.com/llms.txt
Use this file to discover all available pages before exploring further.
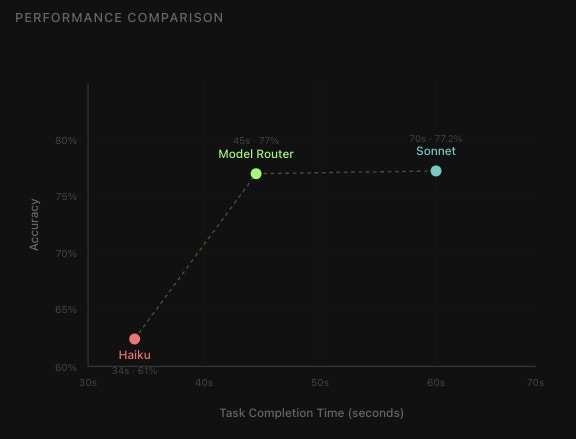
Not every prompt needs a $15/M-token model. A “fix this typo” request and a “design an event sourcing system” request look identical to your API call, but one costs 10x more than it should.
The Morph Router classifies prompt complexity in ~430ms and returns the right model for the job. Trained on millions of coding prompts. $0.005 per request.
Pricing: $0.005/request | Max input: 8,192 tokens
Quick Start
import { MorphClient } from '@morphllm/morphsdk';
import Anthropic from '@anthropic-ai/sdk';
const morph = new MorphClient({ apiKey: "YOUR_API_KEY" });
const anthropic = new Anthropic();
// Router picks the right model
const { model } = await morph.routers.anthropic.selectModel({
input: 'Add error handling to this function'
});
// Use it
const response = await anthropic.messages.create({
model, // claude-haiku-4-5-20251001 (cheap) for simple tasks
max_tokens: 12000,
messages: [{ role: 'user', content: '...' }]
});
Model Selection
The router returns just the model name. Use it directly with your provider’s SDK:
const { model } = await morph.routers.anthropic.selectModel({
input: userQuery
});
// Returns: { model: "claude-sonnet-4-5-20250929" }
Available Models
| Provider | Fast/Cheap | Powerful |
|---|
| Anthropic | claude-haiku-4-5-20251001 | claude-sonnet-4-5-20250929 |
| OpenAI | gpt-5-mini | gpt-5-low, gpt-5-medium, gpt-5-high |
| Gemini | gemini-2.5-flash | gemini-2.5-pro |
Modes
balanced (default) - Balances cost and quality
aggressive - Aggressively optimizes for cost (cheaper models)
// Most use cases
await morph.routers.openai.selectModel({
input: userQuery,
mode: 'balanced'
});
// When cost is critical
await morph.routers.openai.selectModel({
input: userQuery,
mode: 'aggressive' // Uses cheaper models
});
Raw Difficulty Classification
Get raw difficulty classification without provider-specific model mapping:
const { difficulty } = await morph.routers.raw.classify({
input: userQuery
});
// Returns: { difficulty: "easy" | "medium" | "hard" | "needs_info" }
Real-World Example
Route dynamically in production to cut costs while maintaining quality:
import { MorphClient } from '@morphllm/morphsdk';
import OpenAI from 'openai';
const morph = new MorphClient({ apiKey: "YOUR_API_KEY" });
const openai = new OpenAI();
async function handleUserRequest(userInput: string) {
// Router analyzes complexity (~430ms)
const { model } = await morph.routers.openai.selectModel({
input: userInput
});
// Use the selected model
return await openai.chat.completions.create({
model,
messages: [{ role: 'user', content: userInput }]
});
}
// Simple: "Add a TODO comment" → gpt-5-mini
// Complex: "Design event sourcing system" → gpt-5-high
When to Use
Use router when:
- Processing varied user requests (simple to complex)
- You want to minimize API costs automatically
- Building cost-conscious AI products
Skip router when:
- All tasks need the same model tier
- The ~430ms routing latency matters more than cost savings
- You need maximum predictability
API Reference
const { model } = await morph.routers.{provider}.selectModel({
input: string, // Your task description
mode?: 'balanced' | 'aggressive' // Default: balanced
});
// Returns: { model: string }
openai | anthropic | gemini | raw
Raw Router:
const { difficulty } = await morph.routers.raw.classify({
input: string,
});
// Returns: { difficulty: "easy" | "medium" | "hard" | "needs_info" }
Error Handling
Always provide a fallback model:
let model = 'claude-haiku-4-5-20251001'; // Fallback
try {
const result = await morph.routers.anthropic.selectModel({
input: userInput
});
model = result.model;
} catch (error) {
console.error('Router failed, using fallback');
}
// Use model (either selected or fallback)
await anthropic.messages.create({ model, ... });
Edge / Cloudflare Workers
Use @morphllm/morphsdk/edge for edge environments (Cloudflare Workers, Vercel Edge, Deno):
import { OpenAIRouter, AnthropicRouter } from '@morphllm/morphsdk/edge';
export default {
async fetch(request: Request, env: Env) {
const { input } = await request.json();
// Pass API key directly (no process.env on edge)
const router = new AnthropicRouter({ apiKey: env.MORPH_API_KEY });
const { model } = await router.selectModel({ input });
return Response.json({ model });
}
};
The edge entry point exports OpenAIRouter, AnthropicRouter, GeminiRouter, and RawRouter with zero Node.js dependencies.
- Latency: ~430ms average
- Parallel: Run routing while preparing your request
- HTTP/2: Connection reuse for subsequent calls
// Run in parallel to save time
const [routerResult, userData] = await Promise.all([
morph.routers.openai.selectModel({ input: userQuery }),
fetchUserData(userId)
]);
await openai.chat.completions.create({
model: routerResult.model,
messages: [{ role: 'user', content: userData }]
});
When to use
Use the router when:
- Processing varied user requests (simple typo fixes to complex architecture tasks)
- You want to minimize API costs without manually classifying prompts
- Building cost-conscious AI products with mixed complexity workloads
Skip the router when:
- All tasks need the same model tier (e.g., always Opus for agentic coding)
- The ~430ms routing latency matters more than cost savings
- You need deterministic model selection for testing or compliance